100种语言直接翻译!Meta推出SeamlessM4T新模型,核心数据集还开源
时间:2023-08-26 08:22:54 来源:36氪
作者 | 虞景霖
编辑 | 邓咏仪 尚恩
《创世纪》中有这样一个故事,传说在千百年前,地球上所有的人都使用一种语言,有一天他们决定建造一座高塔直通天际,远离洪水的侵扰。
 (相关资料图)
(相关资料图)
这座高塔叫做巴别塔。
很不幸,这件事被神知道了,他们害怕人类因为巴别塔的成功建造而感到骄傲和傲慢,因此决定对人类进行干扰。
于是神打乱了人类的语言,导致人们无法理解对方在说什么。不出神的意料,由于语言不通,人类产生了混乱和分歧,不得不放弃建造巴别塔的计划,四散到了世界各地。
来源:pixabay
而如今,在AI的帮助下,使用不同语言的人可以直接进行交流,重建巴比塔成为可能!
来源:公开网络
这就是Meta发布的AI大模型:SeamlessM4T。一款能够转录和翻译近100种语言的一体化翻译器,目前已在官网免费开放使用。
来源:Meta AI推特
官网体验链接:https://seamless.metademolab.com/
消息一出,就引起了网友的广泛关注,甚至有网友把SeamlessM4T戏称为是“万宝路”创造癌症治疗法。
来源:Jason Ferrell推特
还有网友表示距离《星际迷航》中的万能翻译器又近了一步。
来源:kache(yacine)(e/boy)推特
嗯…..怎么不算呢?
来源:公开网络
但也不是一致好评,有网友就表示SeamlessM4T的表现差强人意,直言:“几乎每次都完全错误”。
来源:minos推特
100种语言直接翻译,文本语音一条龙
不同于仅支持文本转文本的传统翻译器,SeamlessM4T功能众多,具体来说:
能够对96种语言进行语音识别
支持近100种输入和输出语言的语音到文本翻译
支持近100种输入语言和36种输出语言的语音到语音翻译
支持近100种语言的文本到文本翻译
支持近100种输入语言和35种输出语言的文本到语音翻译
来源:Meta AI官网
据官方说明,SeamlessM4T可以分为两个部分,编码器和解码器。
编码器能够识别近100种语言的语音输入,再由解码器将其转化成近100种文本语言或35种(包含英语)语音语言。经过训练的编码器,能够自动识别输入语音中和人类语音对应的音频信号,并将其分解为一系列语音段,最后通过匹配器将这些语音段对应到单词中。
而文本的识别,则基于NLLB模型的文本编码器,经过训练后能理解100种语言的文本内容。基于识别的内容,解码器就可以进行语音和文本的输出。
编码器和解码器实现机制
简单来说,就是把文本或者语音扔给编码器,让它在内部进行一系列解析、分割和转换等操作,再把这些处理好的信息丢给解码器,解码器把他们合成对应语言的文本或者语音。
来源:Meta AI官网
说话间,已经有网友等不及上手玩了起来。
左边这位网友用福建话自我介绍的一瞬间,AI就立即将语句转换为英文,后面即使是“一整段福建话”,SeamlessM4T也应对自如。
来源:Meta
对此就有不少网友开始脑补,有了SeamlessM4T,以后上网组队玩游戏,管你讲啥语言,AI统统都拿下!
来源:Eder Teixeira Eder Teixeira推特
目前,Meta并非唯一一个投入资源用于开发AI转录和翻译的公司。
去年9月,OpenAI就开源了Whisper自动语音识别系统,还强调Whisper的语音识别能力已经达到了人类水准。
而更早之前,互联网鼻祖Netscape旗下的Mozilla基金会,也在2017年推出了公共数据库Common Voice,这是用于训练自动语音识别算法的最大的多语言语音库之一。
在训练数据层面,SeamlessM4T的训练数据似乎没有Whisper那么庞大。OpenAI声称Whisper使用了68万个小时的训练数据,而SeamlessM4T的训练数据约为44万个小时。
那么,Meta的SeamlessM4T强在哪?
来源:公开网络
首先,SeamlessM4T实现了语音和语音之间的直接转换,免除了中间的文本转录过程,能够更好地保留语音特征。
而其他语音转录软件,如Whisper,由于接受了大量的噪音数据的训练,转录的文本中包含实际没说的单词的可能性更高,当语音中包含多种语言的时候,Whisper的转录效果似乎并不那么令人满意。
SeamlessM4T则在这个方面进行了改进,大大增强了模型处理背景杂音和多语言语音的能力。
免费开源,包括核心数据集
目前,Meta将以研究许可证的形式向公众免费提供该模型(仅限非商业用途),以便研究人员和开发人员在此基础上进一步研究。
来源:公开网络
更重要的是,Meta还将发布SeamlessM4T的关键训练数据集之一SeamlessAlign。
这个数据集通过语音识别和文本挖掘技术,从公开渠道抓取并对齐了大量语音和文本数据,覆盖了37种语言,包含了超过44万小时的语音和文本数据,是迄今为止用于多模式翻译的最大的公开数据集。
另外,在测试中团队发现,SeamlessM4T的鲁棒性也灰常不错!
与此同时,Meta还专门做了研究表示,相较于当前最先进的模型,SeamlessM4T在语音转文本任务中处理背景音和变化的语音的能力更强(平均水平分别提高了37%和48%)。
SeamlessM4T鲁棒性测试结果
但和其他众多的AI模型一样,SeamlessM4T也并不是完美的存在,仍然存在多种形式的偏见和误差。
当输入中性词语时,输出的结果偏“男性”。例如,在不明确性别的时候,SeamlessM4T大约有10%的概率倾向将性别表示为男性。Meta推测,这可能是由于训练数据的“男性”倾向更加明显。
除了性别输出偏好,SeamlessM4T还有一些其他的问题。
例如在孟加拉语和吉尔吉斯语等一些语言中,SeamlessM4T对社会经济地位和文化进行了恶意翻译,这类情况在涉及性取向和宗教的翻译中更加严重。而这一点也得到了网友的验证,并表示对此现象的出现十分失望。
来源:Cuenta Libra推特
但是,Meta声称,SeamlessM4T的公开版本中包含了恶意评论的过滤器,能够阻止恶意言论的输入和输出。
但实际情况确是,在模型的开源版本中,默认情况下并没有这个过滤器。也正是由于这个原因,Meta不建议将SeamlessM4T用于过长文本和严肃内容转录翻译。
SeamlessM4T可谓Meta多年来在翻译器开发领域的集大成者。去年,Meta发布了一个能够支持200种语言的文本转文本翻译模型NLLB(No Language Left Behind),还推出了第一个针对闽南语的语音转语音翻译器。
今年5月,Meta推出了一个多模语言翻译器,能够识别并合成1100多种语言的语音。SeamlessM4T综合了上述所有项目的研究成果。
未来,Meta希望基于SeamlessM4T在翻译器开发领域进一步探索,最终创造一个没有语言障碍的世界。
标签:
最新文章推荐
- 100种语言直接翻译!Meta推出SeamlessM4T新模型,核心数据集还开源
- 武汉洪山:天兴洲“变色”啦,这是丰收的颜色
- 股票行情快报:朗博科技(603655)8月25日主力资金净买入34.98万元
- 不得了!今晚,长春这里嗨翻了!
- 2023首届“南开杯”国际跳棋公开赛落幕
- 孙守财(关于孙守财简述)
- 兴业银行济南分行打造精细管理品牌 促进服务品质提升
- 文玩盘玩谈文化觉得尴尬,说盘玩又坚持不下来?到底应该怎么办?优质
- 山西又见平遥演出门票有效期规定
- ⚽墨甲战报:特尔潘卡特尔双响 巴斯克斯补时染红 10人莫雷利亚4-0横扫10人多拉多斯
X 关闭
资讯中心
 河北与京津联手打通拓宽“对接路”2089公里
河北与京津联手打通拓宽“对接路”2089公里
2022-08-15
 兰州理工大学:深挖“战疫”育人新元素构建“大思政”格局
兰州理工大学:深挖“战疫”育人新元素构建“大思政”格局
2022-05-20
2021-10-18
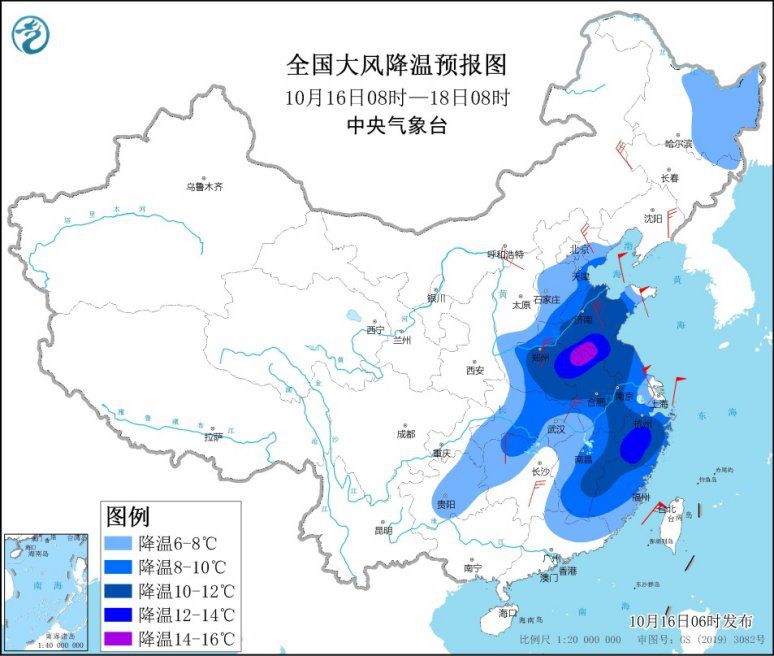 强冷空气继续影响中东部地区 局地降温14℃以上
强冷空气继续影响中东部地区 局地降温14℃以上
2021-10-18
X 关闭
热点资讯
-
1
杏花绽放催热“赏花经济” 吸引了大量游客前来旅游
-
2
上海籍阳性夫妻内蒙古密接、次密接者出现初筛阳性情况
-
3
内蒙古二连浩特:市民非必要不出小区、不出城
-
4
重庆一名潜逃24年的持枪抢劫嫌犯落网
-
5
销售有毒、有害食品 郭美美获刑二年六个月
-
6
陕西新增6名确诊病例1名无症状感染者 西安全面开展排查管控
-
7
《加强建设中国风湿免疫病慢病管理》倡议书:建立基层医院独立风湿科
-
8
游客因未购物遭导游辱骂?九寨沟:相关部门已介入调查
-
9
郭美美再入狱!销售有毒有害食品获刑2年6个月
-
10
2020年黄河青海流域冰川面积和储量较十年前缩减
-
11
5名“摸金校尉”落网 内蒙古警方破获一起盗掘古墓葬案